오늘은 앞전 글에서 다룬 개념 중, Race Condition에 대해서 정리해보겠습니다.
Race Condition
어떤 공유 자원이 있다고 할 때, 해당 자원을 접근하는 두 개의 프로세스가 실행되는 순서에따라 공유 자원이 다른 상태를 가질 수도 있는 경우. 즉, 각 프로세스의 실행이 독립적이 아닌 종속적인 상황을 의미합니다.
아래에는 그러한 상황을 예시로 보여줍니다.

여러 Producer 프로세스가 존재하여, 공유된 자원(Buffer)에 접근하여 데이터를 집어 넣습니다. 그러면 여러 Consumer 프로세스가 그 데이터를 빼서 쓰는 형태의 예시를 들어보겠습니다.
+) 여기서 공유된 자원은 Producer와 Consumer가 프로세스인지 쓰레드인지에 따라 나뉩니다. 프로세스라면 Shared memory겠고, 쓰레드면 한 프로세스의 Data 영역이 될 것입니다.
앞선 예시를 기억하며 진행해보겠습니다.
final int BUFFER_SIZE = 10;
buffer[BUFFER_SIZE]; // 크기가 10인 circular queue
int in = 0; // in은 buffer에서 데이터를 넣을 위치를 가리키는 포인터
int out = 0; // 동일하게 out은 buffer에서 데이터를 뺄 위치를 가리키는 포인터
int counter = 0; // 버퍼에 들어있는 실제 값의 개수이러한 코드가 존재합니다. 그리고 하단에는 메모리의 구조를 간단하게 도식화해보았습니다.
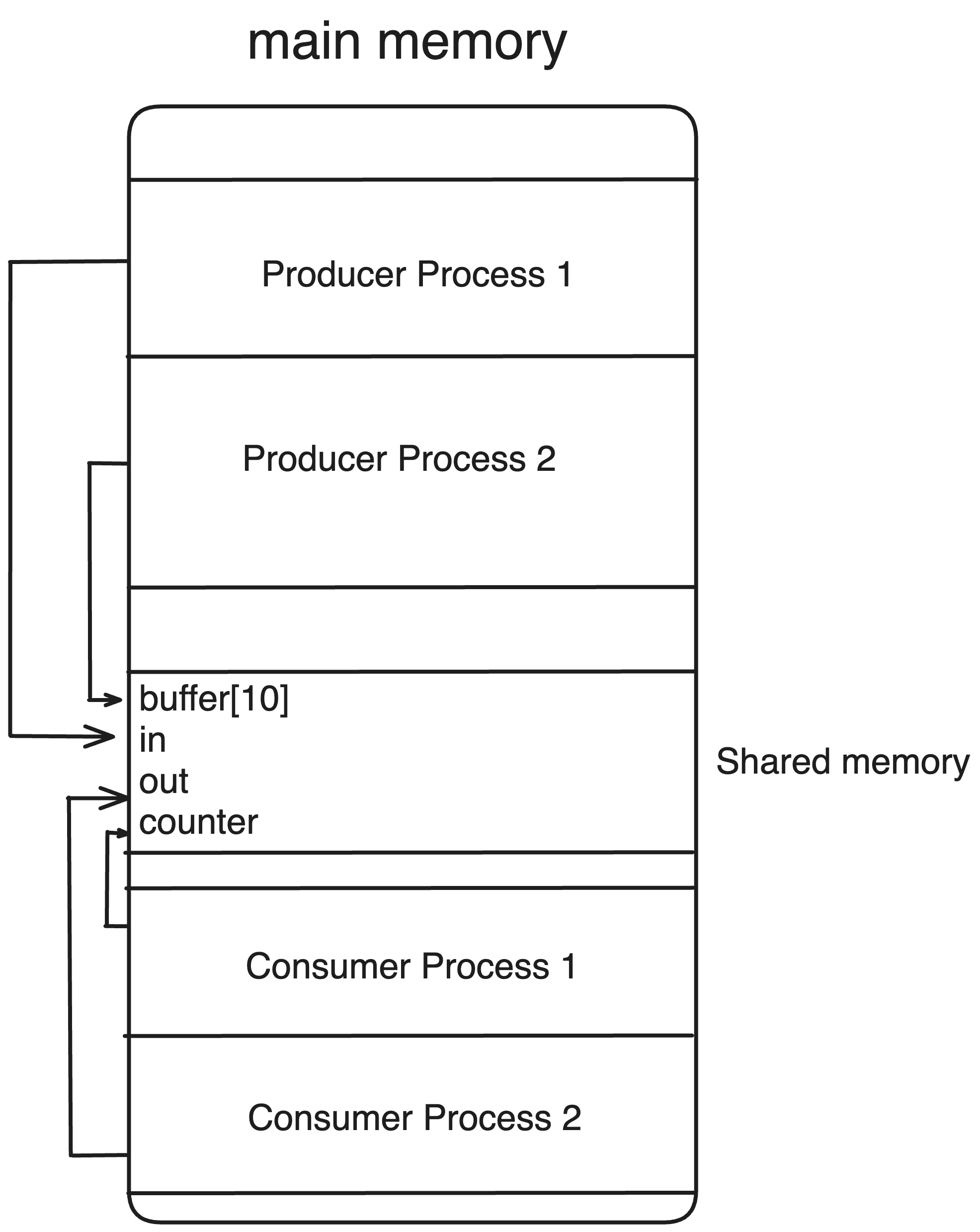
Consumer, Producer는 Shared memory에 다음과 같이 접근할 수 있게 됩니다.
/* Producer */
item v;
while(true){
while(counter == BUFFER_SIZE);
/* item v를 생성하는 instruction */
b[in] = v;
in = (in + 1) % BUFFER_SIZE; // buffer는 circular queue이므로 modular 연산을 수행
counter++;
}Producer는 다음의 instruction을 수행한다고 해봅시다. 이 코드에서의 문제점이 무엇일까요??
만약 counter == BUFFER_SIZE인 상태가 되었다고 해봅시다. 그러면 body가 없는 while문을 계속 돌면서 버퍼에서 데이터가 빠져나가길 기다리게 됩니다.
즉, Buffer가 꽉 찼을 때 Producer에게 프로세스가 배정된다면, 아무 것도 안하고 기다리는 상태로 시간을 소비하게 됩니다. 이것을 busy waiting 이라고 합니다.
/* Consumer */
item w;
while(true){
while(counter == 0);
w = b[out];
out = (out + 1) % BUFFER_SIZE; // buffer는 circular queue이므로 modular 연산을 수행
counter--;
/* consume item w */
}이 또한 마찬가지로 busy waiting이 되겠죠??
사실 위의 코드는 race condition을 충분히 발생시킬 수 있는 instruction입니다. 실제로 보면 아무 이상이 없어보이는데 말이죠. 따라서, 이제 왜 저 코드들이 잘못되었는지를 살펴보겠습니다.
이를 이해하기 위해서는 몇가지 지식들이 필요합니다. 그러한 지식들은 접은 글로 남겨두고 진행하도록 하겠습니다.
Atomically
여기서의 핵심은 Atomic하게 수행되는 것들이 무엇인지를 이해해야합니다. 원자라는 뜻의 Atom에서 따온 것으로, 더이상 쪼갤 수 없는 원자처럼 더이상 쪼갤 수 없는 insturction을 이해해야한다는 것입니다.
저 위의 코드는 high level language로써, 인간이 이해하기 쉬운 언어에 속합니다. 하지만 low-level language인 어셈블리어같은 것들로 사실 기계는 인식하고 동작하므로, 어셈블리어를 우선 알아봐야합니다.(그렇지만 그러기엔 부담스러우니 가볍게만 알아봅시다)
우선 producer와 consumer에서 공통적으로 접근하는 자원인 counter에 대해서 봅시다.
producer는 counter++, consumer는 counter--로 작성되어 있습니다.
counter++는 사실 어셈블리어로 변환하면 3개의 instruction으로 나뉩니다. 편의를 위해 어셈블리어로 작성하지 않고, 단순히 어셈블리어로 나뉘면 어떻게 되는지만 설명하겠습니다.
- counter 변수의 값을 CPU의 register로 LOAD
- register의 값을 1 증가
- register의 값을 counter 주소에 STORE
high-level에서 한 줄의 instruction이 이와같이 3개로 나뉩니다. 이렇게 어셈블리어로 나뉜 instruction은 정말 Atomically합니다.
이제 다시 Atomic을 정의해봅시다. Atomic은 Interrupt의 개입 없이, 온전하게 수행할 수 있는 최소 단위입니다. 따라서 Atomic한 1개의 instruction은 실행했다면, '무조건' 해당 프로세스가 자원을 빼앗기기전에 끝난다는 것을 의미하죠.
알고가면 좋은 개념!! Clock!!
"Clock이 뜬다" 라고 합니다. Clock이 뜰 때, 해당 타이밍에 맞게 설정된 instruction이 수행되게 됩니다. 한 clock동안 하나의 전체 instruction이 수행되는 것은 아니지만, 1개의 Atomic instruction은 꼭 실행됩니다.
보통 process switch는 clock이 100번 들어왔을 때, 일어납니다. CPU 내부에서는 clock이 몇번 튀었는지를 count하는 변수가 존재합니다.
CPU는 T0 상태가 될 때, 일을 수행하기 전, Interrupt가 일어났는지 확인하기 위해 커널모드로 진입합니다. 이 때, count 변수를 통해서 count가 100이 되었는지 확인하고 100이 아직이라면 원래 프로세스로 돌아가고, 100이라면 프로세스 스위치를 합니다.
T0가 무엇인지.. 와 같은 개념은 너무 장황해질 것 같으니,,, 만약 궁금하시다면 제 글 [컴퓨터구조]의 Control Unit을 참고해주세요!!
자! 이제, 다시 앞선 예시로 돌아가서 왜 저러한 코드에서 race condition이 일어날 수 있는 지를 확인해봅시다.
가장 먼저 Producer가 buffer에 값을 넣어야하고, 그 전에 counter가 5라고 해봅시다. 이제 instruction을 수행합니다.
load register, counter (register에는 counter=5가 들어가게 됩니다.)
increment register (register의 값은 6이 될 것입니다.)
이 때 !! clock interrupt가 발생하고, CPU는 Process Switch를 진행하게 되었습니다.(100번 째 clock Interrupt라고 가정합시다)
이제 Consumer가 자원을 할당받았습니다. 이제 Consumer도 자신만의 instruction을 수행합니다.
load register, counter(register에는 counter=5가 들어가게 됩니다. 아직 producer에서 갱신한 6이 counter로 들어오지 않았기 때문이죠)
decrement register(register의 값은 4가 될 것입니다.)
store register, counter(counter에는 register=4가 들어가게 됩니다.)
이제 또, clock interrupt가 발생하여 producer로 프로세스 자원이 할당됩니다.
store register, counter(counter에는 producer의 register=6의 값이 들어가게 됩니다.)
즉, counter는 6의 값을 얻게 됩니다. 만약 위의 초기 상태에서 producer가 아닌 consumer부터 실행했다면, counter는 4가 될 것이구요. 이는 race Condition이고, 따라서 우리는 mutual exclusion을 잘 준수해야합니다.
Prevent Race Condition
그렇다면 이러한 race condition을 어떻게 예방할 수 있을까요?? 두 가지 방법을 소개하겠습니다.
1. critical section을 하나의 Atomic Operation으로 실행하기
말 그대로, 앞서 설명한 3개의 instruction을 하나로 볼 수 있도록 코드를 짜는 것입니다.

이처럼, 단지 counter 변수만 접근하는 간단한 critical section에서는 좋은 방법처럼 보일 수 있죠. 하지만 critical section이 길어지게 된다면, 해당 instruction을 수행하기 위해 많은 시간을 소요하게 될 것입니다. 그렇게 되면, 해당 instruction을 처리하는 동안, 모든 Interrupt를 받을 수 없고 사용자의 I/O 응답 또한 반응할 수 없는 사태에 이를 수 있습니다.
2. fence 만들어 critical section을 감싸기
1번의 단점을 보완하기 위해, fence의 개념을 도입합니다. 이 부분은 다음 글에서 더욱 자세하게 다룰 것이므로, 간단하게만 짚고 갑니다.
fence를 통해서 critical section에는 하나의 프로세스만 들어가게 허용합니다. 따라서 mutual exclusice를 보장하게 되고, interrupt까지 수신할 수 있게 되죠. 즉, 1번의 많은 단점을 보완하게 됩니다.
다음 글에서는 race condition 해결책 중, fence를 통한 SW Solution에 대해서 알아보겠습니다.
'CS > OS' 카테고리의 다른 글
| [운영체제] 6-1. Testset Instruciton (2) | 2023.10.10 |
|---|---|
| [운영체제] 5-3. Critical Section Problem-SW Solution (0) | 2023.10.07 |
| [운영체제] 5-1. 프로세스 동기화 (0) | 2023.10.02 |
| [운영체제] 4-3. 멀티쓰레드 (0) | 2023.10.02 |
| [운영체제] 4-2. 쓰레드 정의 (0) | 2023.09.27 |