인덱스는 내부적으로 균형 트리 형태로 만들어집니다. 균형트리는 자료구조 중 하나로써 범용적으로 많이 쓰이는 구조이니 알아두시면 좋습니다.
균형 트리의 개념
인덱스를 구현하는 데 사용되는 자료구조는 균형 트리입니다. 인덱스로써 쓰이는 균형 트리에 대해 조금 더 자세히 알아봅시다.
균형 트리 구조에서 데이터가 저장되는 공간을 노드라고 합니다. 아래의 그림은 노드 4개가 연결된 상태를 보여줍니다.

이러한 노드라는 용어를 MySQL에서는 페이지라고 부릅니다.
보통 페이지는 가장 작은 저장단위로도 쓰이는데 16Kbyte 정도의 크기를 갖습니다.
전체 테이블 검색
만약 균형 트리 구조를 사용하지 않는다면, 데이터를 검색하는데 어떠한 방식을 사용할까요?
아마도 전체 데이터를 검색하는 방식을 이용할 것 같습니다.
만약 아래와 같이 페이지들이 있다고 해봅시다. (실제 그렇지는 않지만 페이지당 4개의 데이터만 저장할 수 있다고 가정해봅시다)

그러면 아마 3개의 페이지에서 MMM이라는 데이터를 찾기 위해 최악의 경우 모든 페이지를 읽어야할 것입니다.
균형 트리에서의 검색
하지만 균형 트리를 사용하면 그렇지 않습니다.
균형 트리를 이용한다면 페이지가 아래와 같은 형태로 생성되게 됩니다.
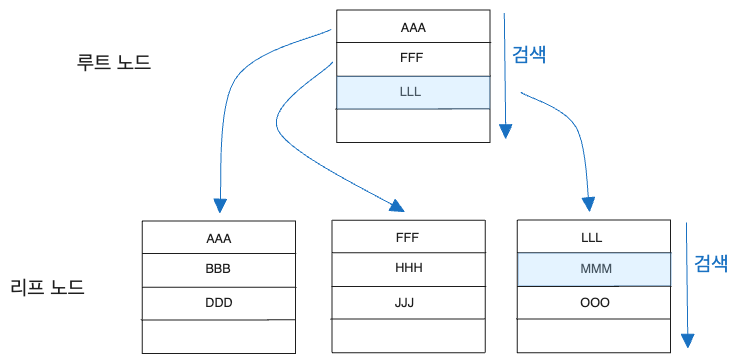
우선 이 형태로 데이터가 만들어지는 과정은 아래에서 알아보기로 하고, 지금은 검색하는 과정만 확인해봅시다.
가장 먼저 루트 페이지에서 MMM은 LLL 다음이므로 LLL 페이지에 있겠구나라고 여기며, LLL 페이지로 이동합니다.
LLL페이지에서 MMM을 찾습니다.
어떤가요?? 균형 트리를 이용하니 페이지를 2개만 읽게 되었습니다. 비록 페이지를 하나 더 쓰게 되지만요.
지금은 데이터의 개수가 매우 적다보니, 페이지를 읽는 양의 차이가 적지만 대규모 데이터베이스를 갖고 있는 회사에서는 이 인덱스가 아주 놀라운 성능을 발휘하게 됩니다.
균형 트리의 페이지 분할
앞서 인덱스는 SELECT 문에서 효과적임을 보았습니다. 하지만 데이터 변경 작업(INSERT, UPDATE, DELETE)이 잦아질 때 효율이 낮아진다고 이전 글에서 다뤘습니다.
그렇다면 이러한 현상이 왜 생기는지 알아볼 필요가 있는데, 이러한 현상의 주된 원인은 바로 페이지 분할입니다.
페이지 분할을 예시와 함께 설명해보겠습니다. 만약 아래와 같은 균형 트리 구조의 데이터가 있다고 해봅시다.

이 상태에서 OOO라는 데이터를 삽입하기 위해서 어떻게 진행될까요??
가장 먼저 OOO가 들어가기 적합한 페이지를 루트 페이지에서 찾아봅시다. OOO는 LLL보다 뒤에 오므로, 아마 LLL 페이지에 들어갈 것 같습니다.
그럼 LLL 페이지에 가서 데이터를 저장하려고 하는데, PPP보다는 OOO가 앞서므로 PPP를 한칸 뒤로 밀고 삽입되게 될 것입니다. OOO가 들어간 상태는 아래와 같습니다.

그렇다면 만약 이 상황에서 데이터가 하나 더 들어오면 어떻게 될까요? 그것도 LLL 페이지(리프 노드의 세번째)에 말이죠. 이제 더이상 해당 페이지에는 들어갈 공간이 없죠?? 이 때, 페이지 분할이라는 작업이 시작되게 됩니다.
페이지 분할은, 페이지에 데이터를 더이상 수용할 수 없을 때, 페이지를 분할하여 데이터를 수용할 수 있도록 트리의 구조를 재조정하는 과정을 의미합니다.
페이지 분할의 과정은 다음과 같습니다.
1. 분할하고자 하는 페이지에서 데이터를 적당히 둘로 쪼갭니다.
2. 쪼개진 페이지의 상태를 루트 노드에 반영합니다. 만약 이 과정에서 루트 페이지에서도 페이지 분할이 필요하다면 동일하게 진행해줍니다. 단, 이 과정에서 기존 루트 페이지는 중간 페이지로 바뀌게 되며, 새로운 루트 페이지가 만들어지게 됩니다.
위 과정을 그림으로 나타내면 아래와 같겠습니다. 아래의 그림은 QQQ라는 데이터를 넣게 된 후의 결과입니다. 루트 페이지에서도 페이지 분할이 이루어지며, 중간 페이지가 만들어지고, 새로운 루트페이지가 만들어졌습니다.

이러한 과정이 여러번 반복되게 된다면 많은 작업이 필요하게 되겠죠?? 즉, 페이지 분할이라는 과정이 필요하기 때문에 데이터의 변경 작업이 빈번한 테이블에서 인덱스는 성능을 저하시킬 수 있는 것입니다.
인덱스의 구조
균형 트리를 통해서 인덱스가 어떻게 작동되는지 대략적으로 알아봤습니다. 하지만 우리는 인덱스가 클러스터형 인덱스와 보조 인덱스로 나뉨을 알고 있습니다. 이 둘은 균형 트리를 통해서 인덱스를 구성하는데 약간의 차이가 존재합니다.
클러스터형 인덱스의 구조
아래의 SQL문으로 데이터를 생성하였다고 해봅시다.
CREATE TABLE cluster (
mem_id CHAR(8),
mem_name VARCHAR(10)
);
INSERT INTO cluster VALUES('TWC', '트와이스');
INSERT INTO cluster VALUES('BLK', '블랙핑크');
INSERT INTO cluster VALUES('WMN', '여자친구');
INSERT INTO cluster VALUES('OMY', '오마이걸');
INSERT INTO cluster VALUES('GRL', '소녀시대');
INSERT INTO cluster VALUES('ITZ', '잇지');
INSERT INTO cluster VALUES('RED', '레드벨벳');
INSERT INTO cluster VALUES('APN', '에이핑크');
INSERT INTO cluster VALUES('SPC', '우주소녀');
INSERT INTO cluster VALUES('MMU', '마마무');
이 떄, 클러스터형 인덱스를 만들기 위해 PK를 지정하여봅시다.
ALTER TABLE cluster
ADD CONSTRAINT
PRIMARY KEY (mem_id);
이렇게 되었다면, 클러스터형 인덱스는 아래와 같은 구조로 형성됩니다.
여기서는 리프 페이지 외에 다른 페이지는 데이터가 7개 들어갈 수 있다고 가정한 상태입니다. 별 의미는 없습니다.

클러스터형 인덱스에서 리프 페이지는 데이터 그 자체입니다. 이는 클러스터형을 영어사전에 빗대어 설명할 떄, 영어 사전의 본문이 책의 찾아보기의 일부라는 것과 같은 개념입니다.
보조 인덱스의 구조
아래와 같은 SQL문으로 보조 인덱스를 위한 테이블을 만들어보겠습니다. 데이터는 클러스터형의 인덱스와 동일합니다.
CREATE TABLE second (
mem_id CHAR(8),
mem_name VARCHAR(10)
);
INSERT INTO cluster VALUES('TWC', '트와이스');
INSERT INTO cluster VALUES('BLK', '블랙핑크');
INSERT INTO cluster VALUES('WMN', '여자친구');
INSERT INTO cluster VALUES('OMY', '오마이걸');
INSERT INTO cluster VALUES('GRL', '소녀시대');
INSERT INTO cluster VALUES('ITZ', '잇지');
INSERT INTO cluster VALUES('RED', '레드벨벳');
INSERT INTO cluster VALUES('APN', '에이핑크');
INSERT INTO cluster VALUES('SPC', '우주소녀');
INSERT INTO cluster VALUES('MMU', '마마무');
이제 보조인덱스를 생성하기 위하여 mem_id를 UNIQUE 로 설정하여 보겠습니다.
ALTER TABLE second
ADD CONSTRAINT
UNIQUE (mem_id);
이렇게 되었다면, 보조 인덱스는 아래와 같은 구조를 띄게 됩니다.

클러스터형 인덱스와 다르게, 인덱스 페이지에서는 리프 페이지에서 데이터 페이지의 주소를 참조하고 있다는 것을 알 수 있습니다. 클러스터형 인덱스는 데이터 그 자체였음인 것과는 확실히 다른 점입니다.
리프 페이지를 제외한 다른 인덱스 페이지에서는 페이지 주소만을 가지고 있지만, 리프 페이지에서는 데이터가 존재하는 페이지의 번호와 해당 페이지에서 얼마나 떨어져있는지(offset)에 대한 정보를 가지고 있습니다.

'CS > DB' 카테고리의 다른 글
| [혼공SQL] 혼공단 11기 - 5주차 미션 인증 (0) | 2024.02.04 |
|---|---|
| [혼공SQL] 인덱스 사용 SQL (0) | 2024.02.01 |
| [혼공SQL] 인덱스의 개념 (0) | 2024.01.30 |
| [혼공SQL] 뷰 (0) | 2024.01.29 |
| [혼공SQL] 제약 조건 (0) | 2024.01.29 |