인덱스를 생성하고 삭제하는 과정에서 사용하는 SQL과 인덱스를 활용한 여러가지를 알아보자.
인덱스 생성 문법
인덱스를 생성하기 위해 사용하는 주 문법은 아래와 같다. 공식 문서의 문법은 아니지만 아래와 같은 형태를 주로 사용하니 참고하자.
CREATE [UNIQUE] INDEX 인덱스_이름
ON 테이블_이름 (열_이름) [ASC | DESC];
UNIQUE는 아래의 두 가지 상황을 충족할 때 사용할 것을 권장한다.
- 현재 해당 열에 있는 데이터가 중복되지 않았을 때
- 추후 입력되는 데이터에서 해당 열의 중복 가능성이 없을 때
ASC, DESC는 인덱스를 오름차순으로 만들 것인지 내림 차순으로 만들 것인지를 결정하는 것인데 기본값이 ASC이며 DESC는 자주 사용하지 않는다.
또한 인덱스는 이름 앞에 idx_를 붙이는 것이 관례이다. 이는 인덱스임을 쉽게 확인할 수 있기 때문이다.
인덱스 제거 문법
인덱스는 아래와 같이 제거할 수 있다.
DROP INDEX 인덱스_이름 ON 테이블_이름;
주의할 점은 기본키, 고유키로 지정된 인덱스는 해당 방식으로 삭제할 수 없으며, ALTER TABLE로 해당 열의 PK나 UNIQUE의 속성을 삭제해주어야 한다.
또한 클러스터형 인덱스와 보조 인덱스가 모두 존재하는 테이블에서는 보조 인덱스를 우선 제거하는 것이 좋다. 만약 클러스터형 인덱스부터 삭제하게 된다면, 쓸데없는 순서로 데이터를 재정렬하는 시간이 소요되기 때문이다.
기타 인덱스 관련 키워드
생성, 조회 뿐만 아니라 인덱스를 조회하는 등의 여러가지 키워드가 존재한다.
SHOW INDEX
해당 테이블에 생성된 인덱스 정보를 보여준다.
SHOW INDEX FROM member;
출력 결과는 다음과 같다.

member에는 mem_id라는 PK가 존재하고, 해당 PK를 기반으로 클러스터형 인덱스가 자동 생성되었기에 위와 같이 출력되었음을 알 수 있다.
SHOW TABLE STATUS
인덱스는 추가적인 공간이 필요하다고 했다. 인덱스가 공간을 얼마나 차지하는지 알아보는 키워드이다.
SHOW TABLE STATUS LIKE 'member';LIKE ~는 해당 조건에 맞는 테이블만 보여주도록 한다. 그렇지 않고는 데이터베이스의 정보를 확인해야하는 'SHOW TABLE STATUS FROM 데이터베이스_이름;' 을 사용해야 한다.
위 쿼리문의 결과로 아래와 같이 출력되었다고 해보자.
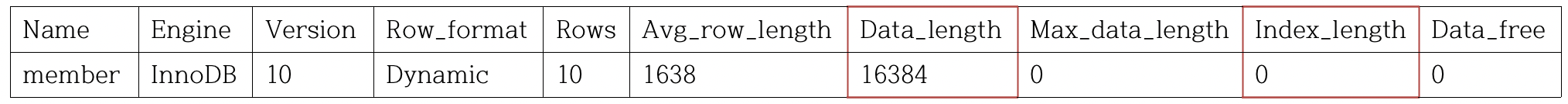
해당 결과에서 Data_length는 클러스터형 인덱스의 크기를 나타낸다. 16,384 = 1,024 * 16이다. 1페이지는 16Kb이므로 1페이지가 할당된 것을 알 수 있다.
ANALYZE TABLE
또한 보조 인덱스의 크기를 나타내는 Index_length는 아직 페이지가 할당되지 않았다. 이는 아직 ANALYZE TABLE문을 실행하지 않았기 때문이다.
보조 인덱스를 생성한 후에는 아래의 쿼리문으로 테이블을 분석/처리해줘야 한다.
ANALYZE TABLE member;

'CS > DB' 카테고리의 다른 글
| [혼공SQL] 스토어드 프로시저 (0) | 2024.02.05 |
|---|---|
| [혼공SQL] 혼공단 11기 - 5주차 미션 인증 (0) | 2024.02.04 |
| [혼공SQL] 인덱스 내부 작동 (1) | 2024.02.01 |
| [혼공SQL] 인덱스의 개념 (0) | 2024.01.30 |
| [혼공SQL] 뷰 (0) | 2024.01.29 |